Antalya University
Course Name: Introduction to Data Science Spring 2020
Course Code: CS 447
Language of Course: English
Credit: 3
Course Coordinator / Instructor: Şadi Evren ŞEKER
Contact: intrds@sadievrenseker.com
Schedule: Tuesday 15.00 – 18.00
Course Description: This course is an introduction level course to data science, specialized on machine learning, artificial intelligence and big data.
- The course starts with a top down approach to data science projects. The first step is covering data science project management techniques and we follow CRISP-DM methodology with 6 steps below:
- Business Understanding : We cover the types of problems and business processes in real life
- Data Understanding: We cover the data types and data problems. We also try to visualize data to discover.
- Data Preprocessing: We cover the classical problems on data and also handling the problems like noisy or dirty data and missing values. Row or column filtering, data integration with concatenation and joins. We cover the data transformation such as discretization, normalization, or pivoting.
- Machine Learning: we cover the classification algorithms such as Naive Bayes, Decision Trees, Logistic Regression or K-NN. We also cover prediction / regression algorithms like linear regression, polynomial regression or decision tree regression. We also cover unsupervised learning problems like clustering and association rule learning with k-means or hierarchical clustering, and a priori algorithms. Finally we cover ensemble techniques in Knime and Python on Big Data Platforms.
- Evaluation: In the final step of data science, we study the metrics of success via Confusion Matrix, Precision, Recall, Sensitivity, Specificity for classification; purity , randindex for Clustering and rmse, rmae, mse, mae for Regression / Prediction problems with Knime and Python on Big Data Platforms.
Course Objective and Learning Outcomes:
1. Understanding of real life cases about data
2. Understanding of real life data related problems
3. Understanding of data analysis methodologies
4. Understanding of some basic data operations like: preprocessing, transformation or manipulation
5. Understanding of new technologies like bigdata, nosql, cloud computing
6. Ability to use some trending software in the industry
7. Introduction to data related problems and their applications
Tools:
List of course software:
· Excel,
· KNIME,
· Python Programming with Numpy, Pandas, SKLearn, StatsModel or DASK
This course is following hands on experience in all the steps. So attendance with laptop computers is necessary. Also the software list above, will be provided during the course and the list is subject to updates.
Grading
One individual term project covering all the topics covered in the course : %100
Project Requirements :
You are free to select a project topic. The only requirement about the project is, you have to cover at least two topics from the following list and solve the same problem with two separate approaches from the list, you are also asked to compare your findings from these two alternative solutions : KNN, SVM, XGBoost, LightGBM, CatBoost, Decision Trees, Random Forest, Linear Regression, Polynomial Regression, SVR, ARL (ARM), K-Means, DBSCAN, HC
Example project topic: you can search Kaggle for some idea about the projects, you can also find some good data sets from these web sites.
Project proposal : until Apr 30 : please explain your project idea and alternative solution approaches from the course content.
Project Deliverables: You are asked to submit the below items via mail until May 19, 2020.
- Presentation and Demo video: please shoot a video for your presentation and demo of your project.
- Project Presentation: slides you are using during the presentation
- Project Report : a detailed explanation of your approaches, the difficulties you have faced during the project implementation, comparison of your two alternative approaches to the same problem (from the perspectives of implementation difficulties, their success rates, running performances etc.), some critical parts of your algorithms. Also provide details about increasing the success of your approach. Please answer all of those questions in your project report: what did you do to solve the unbalanced data if you have in your problem? what did you do to solve missing values, dirty or noisy data problems? did you use dimension transformation like PCA or LDA, why? did you check the underfitting or overfitting possibility and how did you get rid of it? did you use any regularization? did you implement segmentation / clustering before the classification or prediction steps, why or why not? Which data science project management method did you use (e.g. SEMMA, CRISP-DM or KDD?) why did you pick this method? Which step was the most difficulty step and why? How did you optimize the parameters of your algorithms? What was the best parameters and why? how did you found these parameters and do you think you can use same parameters for the other data sets in the future for the same problem?
- Running Code or Project: you are free to implement your solution in any platform / language. The only requirement about your implementation is, you have to code the two alternative solution on the same platform / programming language (otherwise it will not be fair to compare them). Please also provide an installation manual for your platform and running your code.
- Interview: A personal interview will be held after the submissions. Each of you will be asked to provide a time slot of at least 30 minutes for your projects. During this time, you will be asked to connect via an online platform and show your running demo and answer the questions. Please also attach your available time slots to your submissions.
Project Policies: There will be no late submission policy. If you can solve a problem with only 1 approach, which also means you can not compare two approaches, will be graded with 35 points over 100 max. So, please push yourselves to submit two separate approaches for your problem. You are free to use any library during your projects, you are not allowed to use a library or any code on the internet or written by anybody else on the AI part of your project only. So, in other words, you have to write the two different AI module for your project with two different approaches from the course content and using somebodyelse’s code in the AI module will get 0 as the final grade.
Course Content:
| Week 1 (Feb 11): Introduction to Data, Problems and Real World Examples:Some useful information:DIKW Pyramid: DIKW pyramid – WikipediaCRISP-DM: Cross-industry standard process for data mining – WikipediaSlides from first week:week1 |
| Week 2 (Feb 18): Introduction to Descriptive Analytics Repeating the first week for majority of the class and starting the concept of end to end data science projects. Weight and Heigh Sample project and Data Set for Knime work flow. Brief introduction to algorithms: K-NN, Naive Bayes, Decision Trees, Linear Regression |
Week 3 (Feb 25): Introduction to Data Manipulation Concept of Data and types of data : Categorical (Nominal, Ordinal) and Numerical (Interval, Ratio). Basic Data Manipulation techniques with Knime: 1.Row Filter and Concept of Missing Values 2.Column Filter 3.Advanced Filters 4.Concatenate 5.Join 6. Group by , Aggregation 7. Formulas, String Replace 8. String Manipulation 9. Discrete, Quantized Data, Binning 10. Normalization 11.Splitting and Merging 12.Type Conversion (Numeric , String) 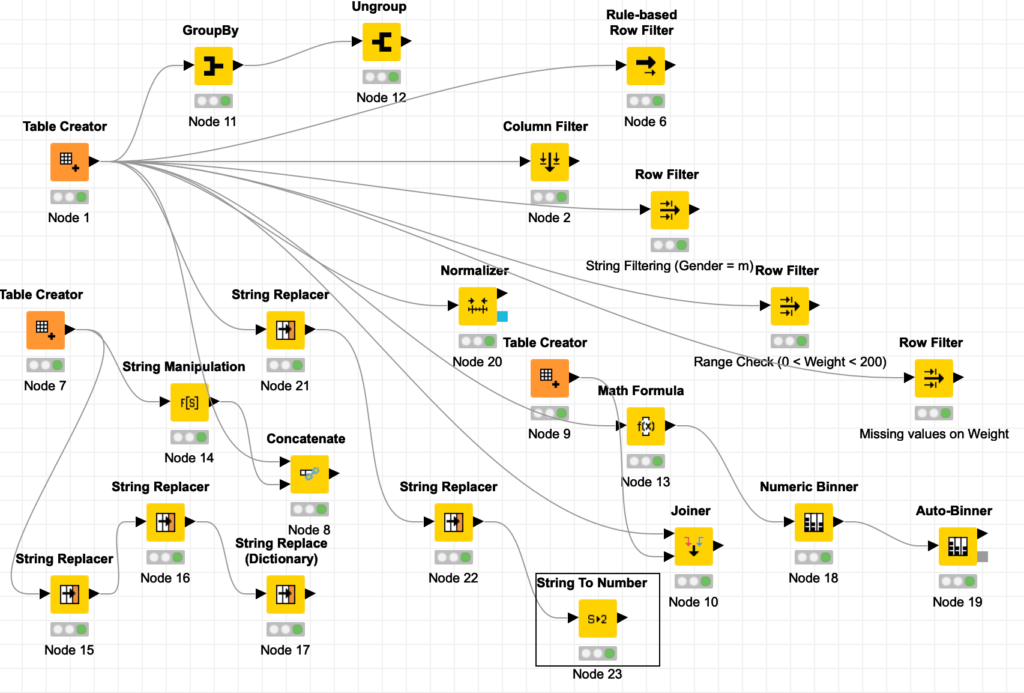 |
Week 4 (Mar. 3): Introduction to Python Programming for Data Science and an end-to-end Python application for data science Brief review of python programming Introduction to data manipulation libraries: NumPY and Pandas Introduction to the Sci-Kit Learn library and a sample classification You can install anaconda and Spyder from the link below:  Also we have covered below topics during the class: Also we have covered below topics during the class:
 Click here to download the codes from the class For further information I strongly suggest you to read the below documentations: Click here to download the codes from the class For further information I strongly suggest you to read the below documentations:
|
Week 5 (Mar 10): Classification Algorithms concepts of classification algorithms, implementing the algorithms in Knime and coding in python. Algorithms covered are: K-NN Naive Bayes Decision Tree Logistic Regression Support Vector Machines 2nd Python Code of the course for the classifications Knime Workflow for the classification algorithms 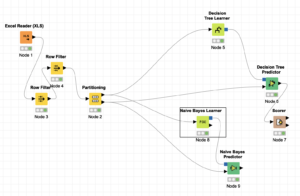 |
Week 6 (Mar 17): Regression Algorithms concepts of prediction algorithms, implementing the algorithms in Knime and coding in python. Algorithms covered are: Linear Regression Polynomial Regression Support Vector Regressor Regression Trees and Decision Tree Regressor Python code for the Regression 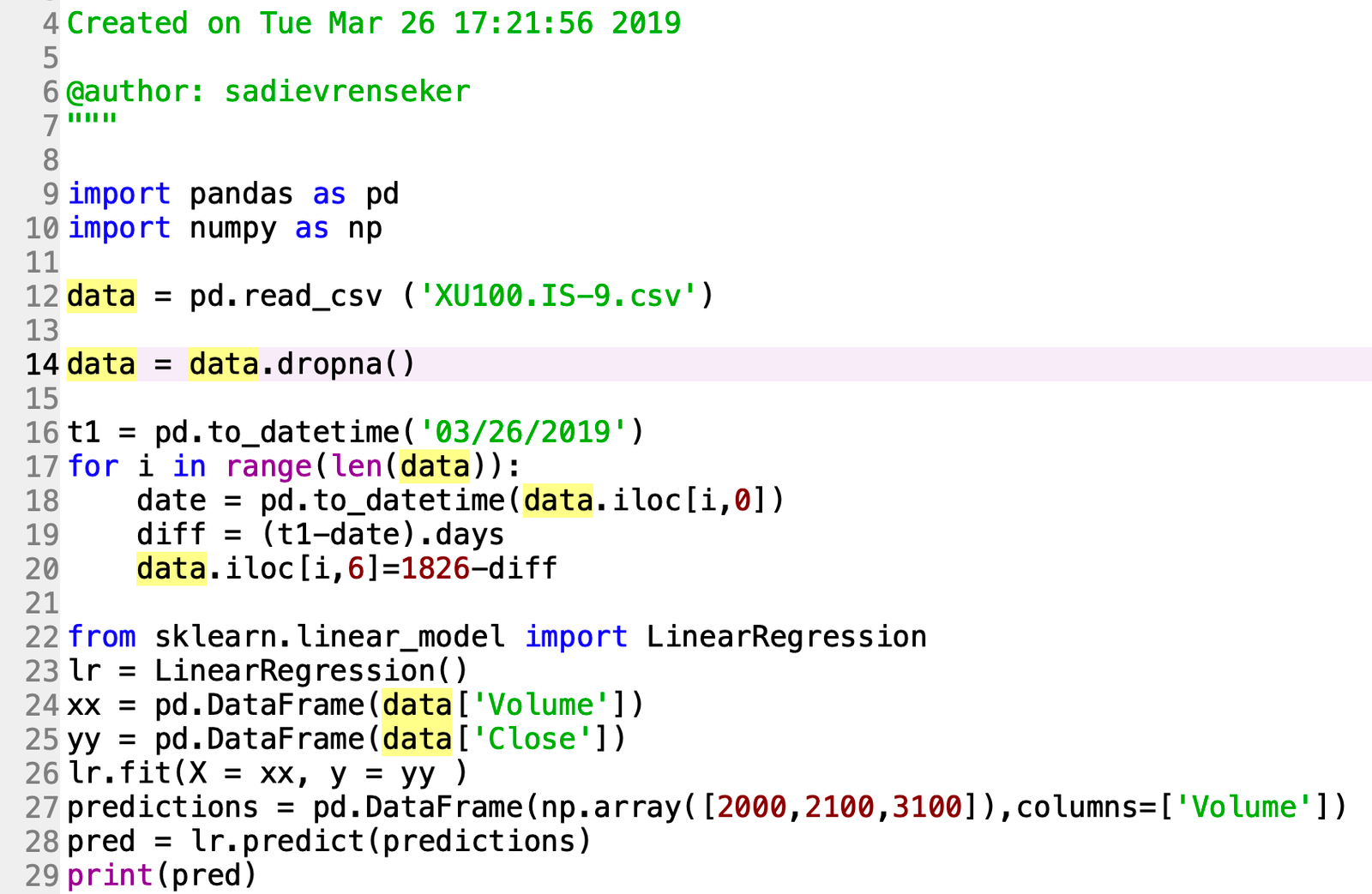 Knime Workflow and the BIST 100 data set for the Regression Algorithms Knime Workflow and the BIST 100 data set for the Regression Algorithms 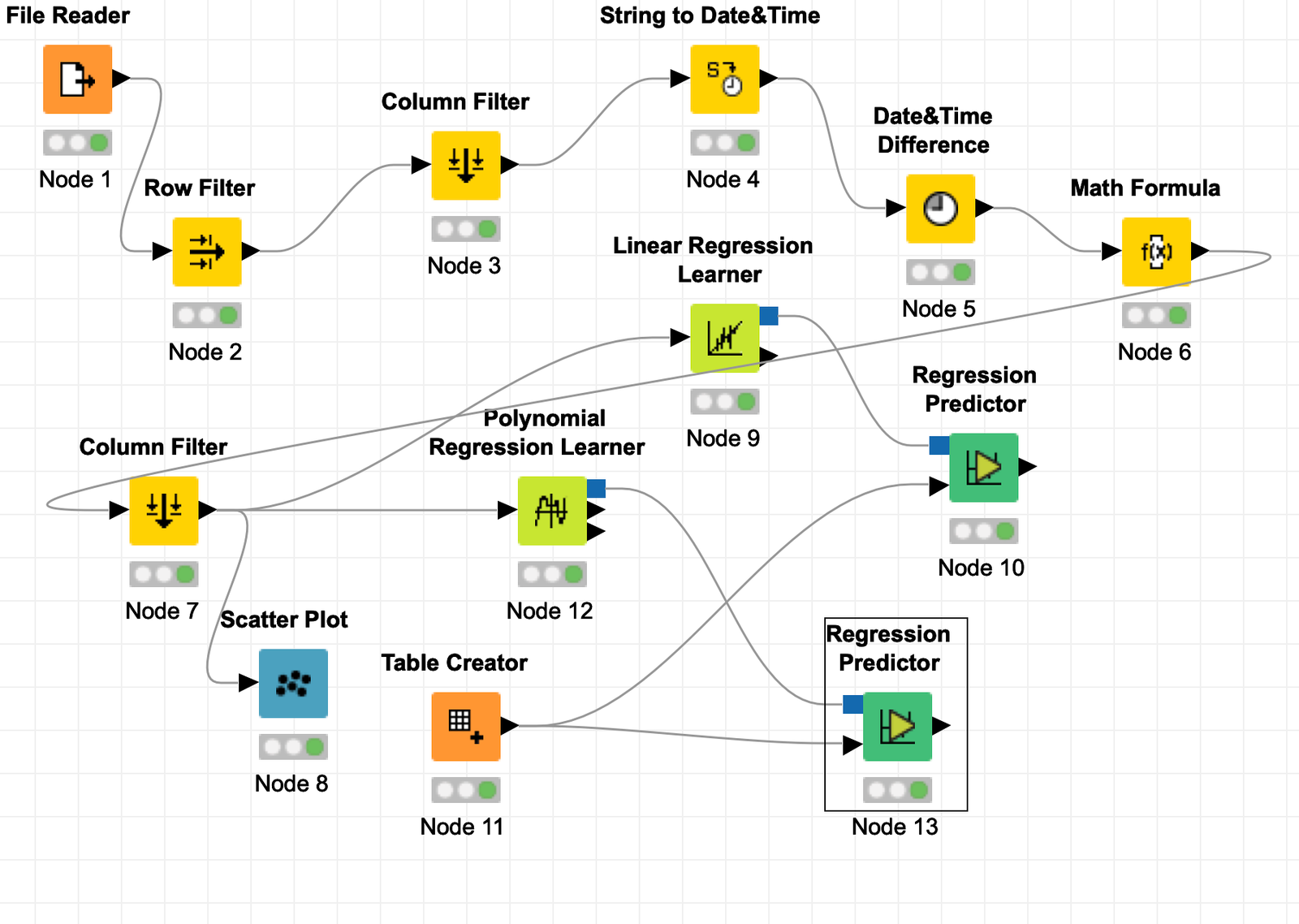 The Data Set obtained from : finance.yahoo.com The Data Set obtained from : finance.yahoo.com |
Week 7 (Mar 24): Clustering Algorithms concepts of clustering algorithms, implementing the algorithms in Knime and coding in python. Algorithms covered are: K-Means DBScan Hierarchical Clustering Knime Workflow  Python Code Python Code 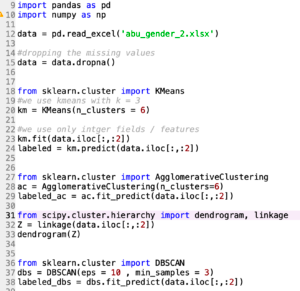 |
Week 8 (Mar 31): Association Rule Mining concepts of association rule mining (ARM) and association rule learning (ARL) algorithms, implementing the algorithms in Knime and coding in python. Algorithms covered are: A-Priori Algorithm Click Here To Download Apyroiri Library for the Python Codes 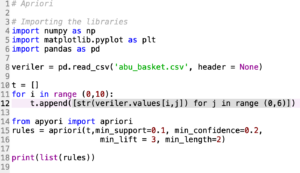 click for python code click for python code 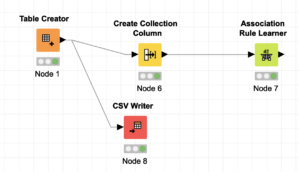 click for knime workflow Homework : Link for Kaggle, instacart click for knime workflow Homework : Link for Kaggle, instacart |
Week 9 (Apr 7): Concept of Error and Evaluation Techniques n-Fold Cross Validation , LOO, Split Validation RMSE, MAE, R2 values for regression RandIndex, Silhouet, WCSS for clustering algorithms Accuracy, Recall, Precision, F-Score, F1-Score etc. for classification algorithms We also got an introduction to dimension reduction with PCA (principal component analysis) and Neural networks with MLP (multi layer perceptron) Please don’t forget to install Keras for next week. 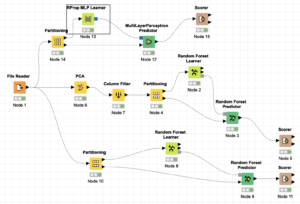  |
| Week 10 (Apr 14): Collective Learning : This content has moved to previous week because of the holiday |
Week 11 (Apr 21): Collective Learning and Consensus Learning and Clustering Algorithms: Ensemble Learning, Bagging, Boosting Techniques, Random Forest, GBM, XGBoost, LightGBM Some links useful for the class:
 XGBoost (for running the code install XGBoost by the command prompt: conda install -c conda-forge xgboost Install XGBoost extension for Knime XGBoost (for running the code install XGBoost by the command prompt: conda install -c conda-forge xgboost Install XGBoost extension for Knime  |
| Week 12 (Apr 28): Project Presentations First Group. Presentations will be picked randomly during the class and anybody absent will be considered as not presented. Project Deliveries (until May 6): Project Presentation, Project Report (explaining your project, your approach and methodologies, difficulties you have faced, solutions you have found, results you have achieved in your projects, links to your data sources). Knime Workflows (in .knwf format) and python codes (in .py format). Please make all these files a single .zip or .rar archive and do not put more than 4 files in your archive. |
| Week 13 (May 5): Project Presentations Second Group If you haven missed the project presentations in the first week, please contact me for further details. |
| Week 14( May 12): TBA |
| Week 15( May 19): TBA |